Распознавание шрифтов по картинке: Как определить русский шрифт по картинке онлайн
04.06.2021 


 Разное
Разное
Как определить русский шрифт по картинке онлайн
Многие из нас проводят в сети огромную часть своего времени. Мы посещаем различные ресурсы, потребляем контент, создаём свои материалы и наслаждаемся постами других людей. Переходя на различные страницы, мы можем наткнуться на сайт, оформление которого выполнено приятным для глаза кириллическим шрифтом. Очарование может быть так велико, что мы можем захотеть такое же оформление и себе. Но как же узнать, каково его название и кто автор? Ниже мы разберём, каким образом можно определить русский шрифт по любому изображению в режиме онлайн. А также какие сетевые ресурсы нам в этом помогут.
Каким образом определить русский шрифт по картинке
Текущая конъюнктура такова, что имеющиеся в сети сервисы для определения шрифта online имеют исключительно зарубежное местоположение. Это означает, что они акцентированы на латиницу, и плохо определяют кириллические символы.
Осознавая подобный «латинский» акцент, ряд мировых стран (Китай, Япония, страны ближнего Востока и др.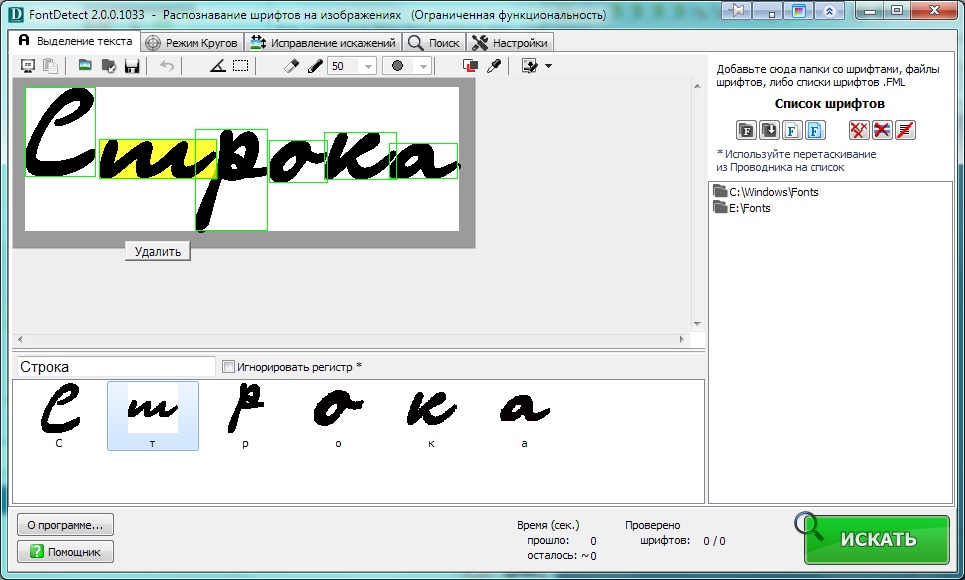
Потому при определении русского шрифта на картинке онлайн нам необходимо ориентироваться на те англоязычные ресурсы, которые лишь частично распознают кириллический шрифт. Нам также помогут различные сетевые форумы, завсегдатаи которых помогут идентифицировать нужный нам вариант.
При этом ряд пользователей идут на различные ухищрения, позволяющие опознать кириллический шрифт. В частности, из кириллического слова вырезаются похожие к латинским буквам (например, О, А, С, Е и другие), после чего изображение с такими буквами загружается на «латинский» сайт. Сайт опознает схожий латинский фонт, который и может быть использован в будущем.
Сама работа с автоматическими идентификаторами шрифтов строится по стандартным лекалам. Вы переходите на такой сайт, загружаете на него ваш шрифт. При необходимости помогаете ресурсу идентифицировать отдельные буквы (вписав их в соответствующие ячейки чуть ниже), и кликаете на кнопку выведения результата.
При необходимости помогаете ресурсу идентифицировать отдельные буквы (вписав их в соответствующие ячейки чуть ниже), и кликаете на кнопку выведения результата.
Давайте разберёмся, какие ресурсы нам могут помочь опознать русское оформление букв в режиме онлайн.
WhatTheFont – определение фонта онлайн
Сервис «WhatTheFont» — один из совсем немногих ресурсов, позволяющих определить кириллические шрифты онлайн. Ресурс обещает поиск в более чем 130 тысячах различных шрифтов, их быструю идентификацию и возможность их приобретения (в случае платных аналогов).
Для работы с сайтом выполните следующее:
- Перейдите на ресурс myfonts.com;
- Кликните на надпись «or click here to upload the image» для загрузки изображения на ресурс;
- После загрузки изображения с помощью рамки укажите часть изображения, на которой находится нужный для распознания кириллический текст.
 Затем нажмите на синий кружочек со стрелочкой;
Затем нажмите на синий кружочек со стрелочкой;Укажите нужный для распознавания шрифт
- Просмотрите найденные совпадения;
- При необходимости вы можете приобрести такой шрифт, нажав рядом на надпись «Get it».
Другим ресурсом, позволяющим найти латинский шрифт похожий на кириллический, является en.likefont.com. Данный сервис является брендом, который развивает азиатский сайт FontKe.com. Здесь представлены веб-алгоритмы, позволяющие идентифицировать шрифт и скачать его на ваш ПК. Поддерживается латиница, японский, китайский, корейский и другие виды шрифтов.
Для работы с ресурсом выполните следующее:
- Запустите likefont.com;
- Нажмите на кнопку «Upload image» ниже, и загрузите вашу картинку на ресурс;
- Щёлкните внизу на «Crop», и установите границы для определения шрифта;
Установите границы для определения шрифта
- Промотайте страницу чуть ниже, и помогите ресурсу опознать некоторые буквы, набрав их правильные аналоги;
- Набрав несколько таких букв, нажмите на «Identify»;
- Просмотрите найденные результаты;
- При необходимости нажмите на «Download» справа для загрузки нужного шрифта на ваш ПК.
Ресурсы для визуальной идентификации
Кроме автоматических идентификаторов, есть также ресурсы, позволяющие найти нужный кириллический шрифт онлайн, что называется, «на глаз». Принцип их работы состоит в следующем. Вы переходите на такой ресурс, вбиваете в специальное поле какое-либо русское слово (фразу), и просматриваете варианты надписей данной фразы на разных кириллических шрифтах. Сравниваете с оригиналом и находите точное совпадение.
Среди таких ресурсов отметим следующие:
| Ссылка: | Описание: |
|---|---|
| catalog.monotype.com | Англоязычный ресурс, работающий и с кириллическими шрифтами. Ваше слово набирайте в поле «TYPE YOUR TEXT». |
| fontov.net | Популярный отечественный ресурс с большой базой шрифтов. Визуальная идентификация работает схожим образом с другими аналогами. Вводите нужную фразу в соответствующее поле на сайте, и нажимаете справа на «Ок». Сервис позволяет скачать понравившийся шрифт на ваш ПК. Сервис позволяет скачать понравившийся шрифт на ваш ПК. |
| fonts-online.ru | Ещё один отечественный сервис с множеством бесплатных шрифтов. Поле для ввода вашей фразы находится справа. |
| fonts.by | Несмотря на обилие кириллических шрифтов, форма для ввода своего слова для поиска здесь отсутствует. Придётся искать среди шрифтов самостоятельно, с обилием затраченного времени. |
Специализированные форумы для определения шрифта
Кроме указанных ресурсов нам могут помочь специализированные форумы, на которых можно встретить опытных в графическом дизайне специалистов. В частности, рекомендуем такой форум как fontmassive.com, в котором вы можете выложить изображение с понравившимся шрифтом, спросить о его названии и источнике скачивания.
Спросите о шрифте у обитателей форумаТакже следует присмотреться к следующим форумам:
- flickr.com;
- myfonts.com/forum;
- typophile.com и другие аналоги.
Спросите название у разработчика сайта
Кроме перечисленных сервисов, вы можете попытаться спросить название использующегося на сайте шрифта непосредственно у администратора сайта. Найдите внизу форму для обратной связи, и напишите письмо администрации, не забыв указать свой обратный е-мейл. Есть большая вероятность, что вам ответят.
Читайте также: как распознать шрифт по картинке онлайн.
Заключение
В нашем материале мы разобрали, каким образом можно идентифицировать русский шрифт по любой картинке в режиме онлайн. А также какие сетевые сервисы окажут нам в этом посильную помощь. Несмотря на ограниченное количество работающих с кириллицей ресурсов, вы можете воспользоваться как перечисленными альтернативами, так и сетевыми форумами. На последних вам поможет «человеческий фактор», способный на опыте определить точное название нужного вам шрифта.
Распознавание русского шрифта онлайн | Mannodesign.com
По запросу «Распознавание русского шрифта онлайн» ко мне все чаще и чаще заглядывают в последнее время. Ну что ж, тема весьма актуальная. Сама не раз сталкивалась с необходимостью найти русский шрифт, увиденный на картинке. Бывает, что заказчик предоставляет свое лого с русским шрифтом, но естественно, он совершенно не знает, что это за шрифт. Хорошо, если исходники сохранились, но это редкость. И поиск шрифта по картинке превращается в безуспешное рытье Интернета.
Я уже как-то рассказывала про Онлайн инструменты для распознавания шрифта. К сожалению, буржуйские сервисы не умеют распознавать русские шрифты. И в действительности онлайн инструментов для распознавания русского шрифта пока не существует.
Для себя я нашла достаточно простой и вполне рабочий способ распознавания русских шрифтов.
Дело в том, что наши дизайнеры практически не заморачиваются созданием оригинального шрифта, а используют те, что уже есть. Поэтому достаточно зайти на любой сайт с коллекцией русских шрифтов и поискать требуемый шрифт просто по ключевым характеристикам: с засечками, без засечек, рукописные, ретро, гранж и т.п.
Вот несколько таких сайтов с коллекциями русских шрифтов:
xfont.ru
fontov.net
fonts.by
fonts2u.com
nifa.ru
В большинстве случаев, найти идентичный шрифт не составляет особого труда. Хотя порой приходится постараться.
А вы думали, все так просто? 🙂
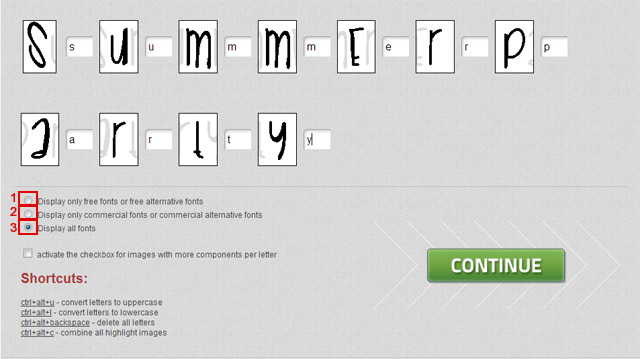
Еще вариант — использовать те же буржуйские сервисы WhatTheFont и WhatFontiS.com, про которые я рассказывала ранее. Берем с картинки только те буквы, которые есть и в латинице: о, т, у, р, в, м, н, у, х, а, с. И вводим их на латинице в указанных сервисах. Бывает, что таким образом можно найти нужный шрифт, а потом уже по его названию можно поискать такой же на кириллице.
UPD 02.03.2015: Нашла один русскоязычный сервис по распознаванию кириллических шрифтов FontDetect Online. К сожалению, на сегодняшний день он, как онлайн сервис, не работает. Можно лишь скачать прожку, которая будет искать шрифт по картинке среди указанных вами же шрифтов. Но зато там есть тусовка, где народ кидает вопросы с картинками и получает ответы. Так что можно порыться среди ответов и найти что-то полезное.
Не знаете, что выбрать? Прочитайте статью «Я не знаю, чего я хочу».
Как найти нужный шрифт, не зная его названия? / Хабр
Я уверен, что у любого дизайнера был такой момент, когда он видел где-то какой-то шрифт, который так мог бы пригодится в проекте, но… что за шрифт?.. Ответ на этот вопрос затаился в глубине Вашего сознания, либо в глубине Вашего «незнания» (что разумеется простительно).В этой статье мы рассмотрим несколько ресурсов, которые могут помочь вам в идентификации понравившегося шрифта.
Конечно, нельзя рассчитывать, что эти источники дадут вам 100 процентную уверенность в том что вы найдете нужный шрифт, но что помогут, так это точно.
What The Font?!
Graphic Design Blog полезный ресурс, но может помочь лишь в том случае, если вы знаете имя дизайнера или студию, создавшего шрифт. Список студий и дизайнеров весьма обширный и поиск шрифта в разы упрощается. Но, что делать, если вы видите шрифт в первый раз?
Могу сказать, что получаются довольно-таки неожиданные результаты.
Шаг 1: Загрузите картинку. Если картинка с фоновым шумом или с недостаточным контрастом, будь добры потратить несколько минут в Photoshop, что бы довести картинку до ума.
Шаг 2: После загрузки картинки, проверьте, что What The Font правильно определил глифы, и лишь после этого жмите «поиск».
Вкратце, ГЛИФ — это графический образ знака. Один знак может соответствовать нескольким глифам; строчная «а», капительная «а» и альтернативный вариант строчной «а» с росчерком являются одним и тем же знаком, но в то же время это три разных глифа (графемы).
С другой стороны, один глиф также может соответствовать комбинации нескольких знаков, например лигатура «ffi», являясь единой графемой, соответствует последовательности трех знаков: f, f и i. Т.о. для программы проверки орфографии слово suffix будет состоять из 6 знаков, а графический процессор выдаст на экран 4 глифа.
Сначала я загрузил эту картинку:
В результатах поиска, What The Font мне выдал 24 варианта. К чести What The Font могу сказать, что некоторые шрифты из списка были похожи на Adobe Garamond Pro.
Но я загрузил маленькую картинку.
Увеличив размер картинки (максимум 360 на 275 пикселей), список резко сократился:
Minion Regular Small Caps & Oldstyle Figures
Minion Regular
Adobe Garamond
Где, как вы видите, нашелся и правильный шрифт (хотя не совсем точно, между Adobe Garamond и Adobe Garamond Pro, все-таки разница, хоть и небольшая, но есть), если бы я увеличил размер картинки еще больше, то идентификация прошла бы успешно, но мне уже было лень проверять.
Если же What The Font не смог определить шрифт, то Вам в помощь его форум, местожительство шрифтовых гурманов, где вам обязательно помогут с поиском.
Typophile
Отличное сообщество, огромное количество ресурсов, блогов, новостей связных с типографской культурой. Есть даже typography Wiki.
Да, у Typophile нет автоматического идентификатора шрифтов, но зато имеющееся сообщество поможет Вам гораздо лучше, чем какая-то программа.
FontShop
Еще один отличный сайт по типографике. Одно название говорит, само за себя. Обширный контент, блог, часто обновляемые новости и обзоры.
Подход Fontshop в определении шрифта оригинален: сначала вы определяете общую форму шрифта, затем по нарастающей, вы отвечаете на все более сложные вопросы.
Это сервис хорош, не только как инструмент, который помогает идентифицировать шрифт, но и как отличное подспорье для поиска подходящих для вашего проекта шрифта.
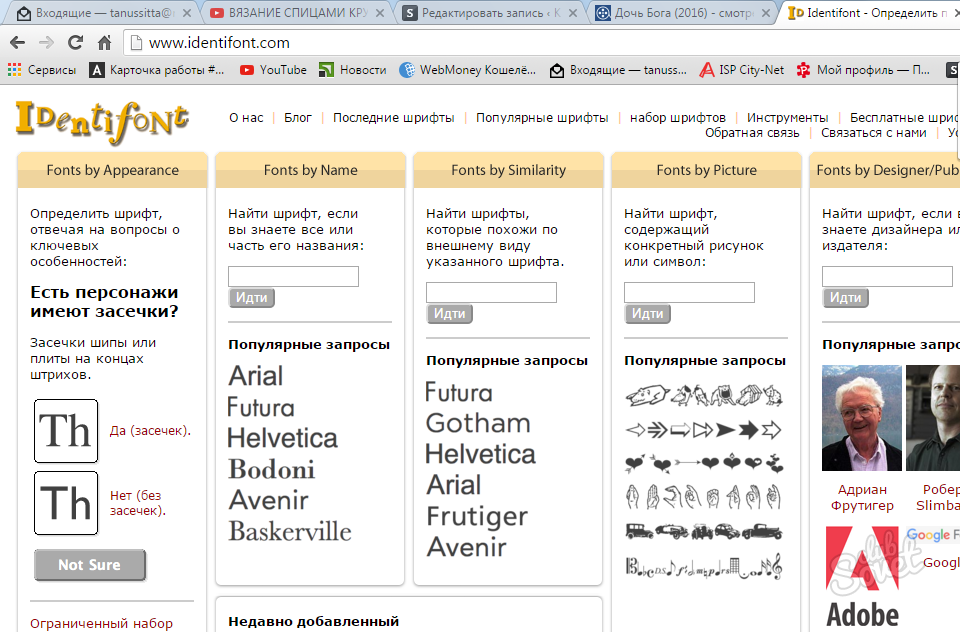
Identifont
Это сайт, дает новый поход к поиску с относительным результатом.
 Identifont задает вопросы, по типу «Имеют ли буквы серифы?» или «Какой формы серифы?»
Identifont задает вопросы, по типу «Имеют ли буквы серифы?» или «Какой формы серифы?»После этого, Identifont постарается дать ответ на основе заданных вопросов.
Да, конечно, определить неизвестный шрифт нелегко. Никто наверняка не знает, сколько шрифтов было создано за всю историю типографики. Как бы то ни было, он точно есть среди сотни тысяч шрифтов.
Процесс поиска нужного шрифта нельзя назвать бесполезным. Во время поиска, Вы найдете массу интересного не только по какому-то определенному шрифту, но в целом по его собратьям.
Хотя, это уже философия, так как это правило можно применить к любому делу.
Удачного поиска!
Вольный и упрощенный перевод статьи — Identify That Font.
Распознавание текста онлайн с картинки, pdf в текст: обзор сервисов
Доброго времени суток, уважаемый посетитель, блога inetsovety.ru! Из этой статьи вы узнаете, какие есть сервисы и программы, помогающие распознать текст онлайн с jpeg картинки или pdf файла в ворд.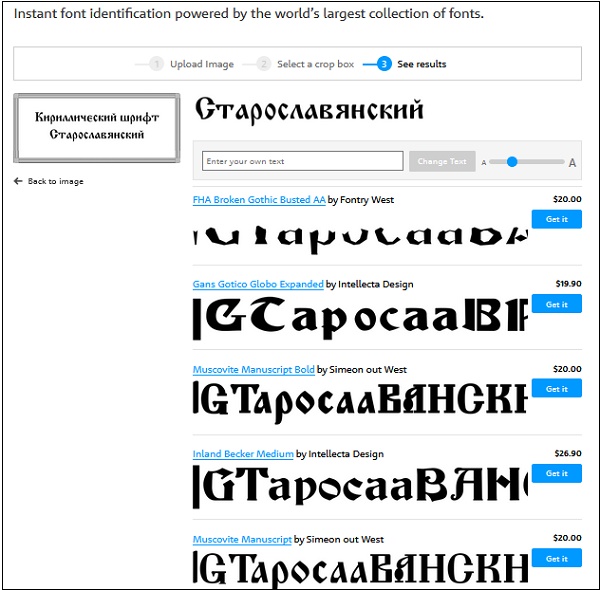 Бесплатно перевести картинку в текст онлайн можно на многих сайтах, но все они имеют свои особенности и ограничения, об этом мы и поговорим далее.
Бесплатно перевести картинку в текст онлайн можно на многих сайтах, но все они имеют свои особенности и ограничения, об этом мы и поговорим далее.
Сразу хочу заметить, что для больших объемов документов, страниц книг, лучше использовать программы для распознавания текста со сканера. Есть как дорогие варианты — Abbyy Finereader, так и бесплатные, например CuneiForm.
Если число сканированных страниц текста небольшое или потребность преобразовать изображение в текст возникает не часто, быстрее всего считать текст с картинки онлайн.
Сервисы бесплатного распознавания текста с фото онлайн
Хочу заменить, что качество, получаемое при считывании текста с картинки, зависит от следующих факторов:
- качества исходника;
- размера элементов и четкости символов на отсканированном материале;
- формата файла.
Вашему вниманию представляю подборку сервисов, позволяющих преобразовать картинку в текст онлайн. Большинство из них бесплатные, а об имеющихся ограничениях, я упомяну в отдельной таблице. Большинство сайтов на английском языке.
Большинство сайтов на английском языке.
Сравнение онлайн распознавателей текста с фото или PDF смотрите в таблице ниже:
к оглавлению ↑Сервис от Гугл
Чтобы перевести с текст с фото в ворд понадобится электронная почта gmail. С ее помощью вы получите доступ ко многим сервисам от Google. Ограничений по количеству файлов нет, как и по их объему.
Переходите по ссылке drive.google.com в хранилище файлов Мой диск. Сначала загрузите файл на виртуальное облако:
После этого кликаете по нему правой кнопкой и выбираете в меню открыть с помощью “Google Документы”:
Результат перевода текста с картинки в ворд будет помещен в Google Документы и откроется на соседней вкладке. Далее вы можете его там редактировать или скопировать на компьютер в одном из форматов:
к оглавлению ↑Abbyy Finereader Online
Это онлайн распознаватель текста с pdf или изображения в word, аналог одноименной программы для ПК. Файн ридер онлайн позволяет бесплатно распознать до 5 страниц в месяц и то только после регистрации. Плюс бонусом предоставляется 10 страниц после подтверждения имейла. Стоимость платного пакета услуг — 129 € / год на 5000 страниц.
Плюс бонусом предоставляется 10 страниц после подтверждения имейла. Стоимость платного пакета услуг — 129 € / год на 5000 страниц.
Как использовать сервис показано на скрине — всего 5 шагов к получению текста с фото или pdf в ворд онлайн:
Ссылка для перехода finereaderonline.com
к оглавлению ↑Online OCR
Отличный сервис распознавания текста с фото или из pdf с приемлемыми ограничениями в формате гостевого доступа, т.е. без регистрации на сайте. Позволяет произвести преобразование картинки в текст онлайн в количестве до 15 штук в час или 15 страниц в многостраничном PDF файле. Обратите внимание, что для работы с PDF документами понадобится регистрация.
Ссылка на сам сервис OnlineOCR.net
Как вытащить текст из картинки в word этим сервисом смотрите ниже на скрине:
к оглавлению ↑Отличительная особенность — в получаемых результатах изображения сохраняются с текстом. В других сервисах, что будут описаны ниже такого нет.
Free Online OCR
Довольно неплохой бесплатный и не имеющий ограничений по количеству файлов переводчик текста с картинки онлайн.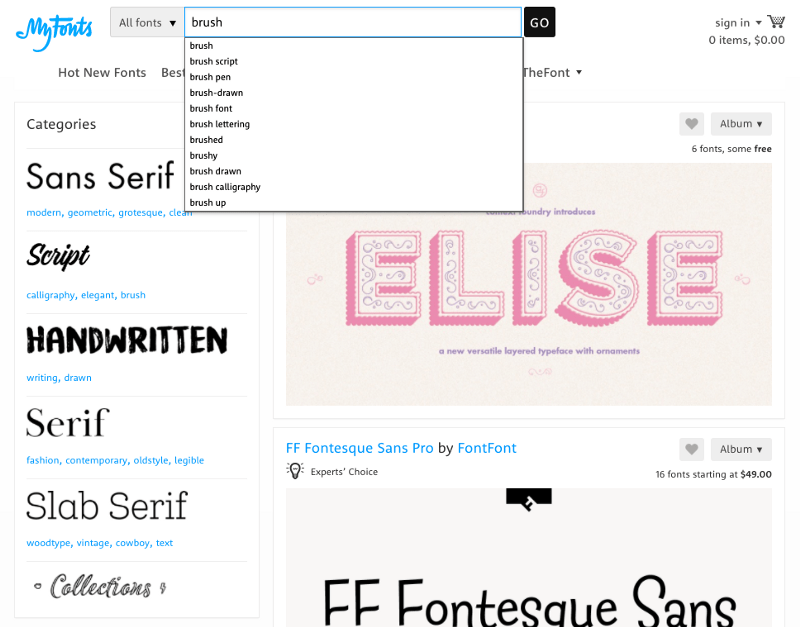 Один его недостаток — сохранение результата без изображений с источника.
Один его недостаток — сохранение результата без изображений с источника.
Для открытия сайта кликните newocr.com
Выбираем файл, ниже уже будет добавлено 2 языка, при необходимости добавьте другие. Кликните по кнопке «Upload & OCR»:
Изображение будет автоматически загружено и распознано. Результаты можно сохранить в документ или скопировать прямо из сайта:
к оглавлению ↑Есть возможность выделить участок на изображении для распознавания. А также несколько разных языков.
OCR Convert
Распознавание текста с картинки онлайн сервисом OCR Convert происходит не мгновенно! Вам предлагают оставить имейл, на который придет оповещении об удачном завершении распознавания. И скачать готовый файл можно в течении 24 часов, дальше он будет удален автоматически. Это главный минус данного сайта!
Работать просто, выберите файл, язык и кликните по кнопке «Convert»:
к оглавлению ↑Soda PDF OCR
Многофункциональный сервис для работы с PDF документами. Полный список возможностей представлен на скрине ниже, но нас в первую очередь интересует распознавание текста из pdf в word онлайн.
Полный список возможностей представлен на скрине ниже, но нас в первую очередь интересует распознавание текста из pdf в word онлайн.
Для распознавания текста из пдф в ворд в меню выберите «Other Tools» — «OCR PDF» или перейдите по ссылке www.sodapdf.com/ocr-pdf:
Загрузите файл и получите расшифрованный документ.
к оглавлению ↑I2OCR
Еще один сервис предоставляющий бесплатное распознавание текста по картинке без ограничений по количеству файлов. Для перехода кликните по ссылке www.i2ocr.com
Работать с сайтом просто, всего 4 действия, чтобы преобразовать фото в текст:
- Выбираем язык.
- Загружаем файл.
- Подтверждаем, что мы не робот.
- Кликаем по кнопке «Extract».
Ожидаем минутку и появляется возможность скопировать текст с картинки онлайн на свой компьютер в одном из форматов по кнопке «Download».
к оглавлению ↑OCR от Яндекс
Его назначение — перевод текста из подгруженного изображения, но с задачей сканировать текст с фотографии онлайн он успешно справляется. Работает без регистрации и каких-либо ограничений.
Работает без регистрации и каких-либо ограничений.
Алгоритм работы прост — перейдите на сайт. Перетащите файл или воспользуйтесь загрузкой по кнопке. И кликните по ссылке «Открыть в Переводчике». Текст вероятнее всего не будет переведен, но удастся извлечь текст из картинки онлайн. Сохранение не предлагается, вы вручную выделяете и копируете текст в любой текстовый редактор, установленный на компьютере и потом сохраняете.
Вот таким не хитрым способом, используя яндекс переводчик не по назначению нам удалось скопировать текст с картинки онлайн.
В статье были рассмотрены различные сервисы помогающие распознать картинку или пдф онлайн. Подбирайте для себя наиболее подходящий. Пишите свои впечатления от работы с ними в комментариях к статье. Всем успехов!
С уважением, Виктория – блог inetsovety.ru
Как распознать шрифт? — Мини-руководство по успешному распознаванию шрифтов — Содержание — Форумы SitePoint
4. Подсказки
Подсказки
• WhatTheFont
Подготовка образа
Есть несколько советов, которые помогут WhatTheFont распознать шрифт из предоставленного изображения.
Это следующие:
- увеличение контрастности
- Удаление устаревших, не относящихся к шрифту элементов
- увеличение межбуквенного интервала
Изображение, которое выглядит следующим образом:
Для WhatTheFont было бы сложно распознать шрифт, и он, скорее всего, потерпит неудачу.
После некоторой работы изображение можно превратить в это:
Это исправление значительно увеличит шансы на успех в поиске правильного соответствия шрифта.
Выбор оптимального набора букв
Если образец вашего шрифта содержит больше букв, вам следует подумать о выборе оптимального набора для WhatTheFont.
WTF имеет некоторые ограничения:
- количество деталей — макс. 35 Максимальный размер изображения
- — около 360 x 275 пикселей * ʾ
* ʾ Чем меньше высота изображения, тем больше ширина.
Хотя количество компонентов обычно не является проблемой, ограничение размера изображения может привести к тому, что для распознавания шрифта будет предоставлено меньше символов, а значит, и шансы на успех будут меньше.
Нет смысла загружать изображение, в котором одна и та же буква встречается несколько раз.
Повторяющиеся символы могут быть удалены и заменены уникальными.
Помните, что WhatTheFont не является инструментом OCR (оптического распознавания символов).
Не имеет значения, имеют ли загружаемые вами буквы какой-то смысл, это всего лишь образцы символов.
Пример:
Вместо «массового стресса проходит» лучше удалить все повторяющиеся буквы (оставив только «mas tre p») и добавить несколько уникальных букв.
Чем больше разнообразия предоставленных символов, тем больше шансов на успешное распознавание шрифта.
• Сравнить и сопоставить
Категории шрифтов
Отсортируйте коллекцию шрифтов по категориям логических стилей (готика, шрифт, пиксельное / растровое изображение и т. Д.)
Д.)
Если вы не знаете, как их отсортировать, используйте категории, указанные на DaFont или аналогичном сайте бесплатных шрифтов.
Это очень поможет вам при поиске определенного стиля шрифта.
Исходники шрифтов
Для успешного использования метода «Сравнить и сопоставить» ваша коллекция шрифтов должна быть большой.
Вы можете загружать шрифты с множества сайтов бесплатных шрифтов — ознакомьтесь с полным списком популярных шрифтовых сайтов.
Программа просмотра шрифтов
Если у вас еще нет программы просмотра шрифтов или диспетчера шрифтов, вам придется загрузить и установить его.
Есть несколько бесплатных или условно-бесплатных программ:
• FontHit
• FontView
• Font Xplorer Lite
• X-fonter
Есть и коммерческие программы, но любой из упомянутых должно хватить для этой задачи.
Найдя искомый шрифт, вы можете подтвердить соответствие, введя текст в поле «пользовательский предварительный просмотр» на сайте шрифтов, например, www. dafont.com.
dafont.com.
Процедура
• решите, к какой категории стилей относится шрифт
• запустите программу просмотра шрифтов
• введите те же буквы (в качестве образца текста), что и на изображении с неопознанным шрифтом
• медленно просмотрите категорию шрифта, сравнивая образец текст с изображением
Оптическое распознавание символов (OCR) — Компьютерное зрение — Azure Cognitive Services
- 6 минут на чтение
В этой статье
API компьютерного зрения Azure включает возможности оптического распознавания символов (OCR), которые извлекают печатный или рукописный текст из изображений.Вы можете извлекать текст из изображений, например фотографий номерных знаков или контейнеров с серийными номерами, а также из документов — счетов, счетов, финансовых отчетов, статей и т. Д.
Д.
Читать API
Computer Vision Read API — это новейшая технология распознавания текста в Azure (узнайте, что нового), которая извлекает печатный текст (на нескольких языках), рукописный текст (только на английском языке), цифры и символы валюты из изображений и многостраничных документов PDF. Он оптимизирован для извлечения текста из изображений с большим объемом текста и многостраничных PDF-документов на разных языках.Он поддерживает обнаружение как печатного, так и рукописного текста в одном изображении или документе.
Входные требования
Вызов Read принимает изображения и документы в качестве входных данных. К ним предъявляются следующие требования:
- Поддерживаемые форматы файлов: JPEG, PNG, BMP, PDF и TIFF
- Для файлов PDF и TIFF обрабатывается до 2000 страниц (только первые две страницы для бесплатного уровня).
- Размер файла должен быть менее 50 МБ (4 МБ для уровня бесплатного пользования) и размером не менее 50 x 50 пикселей и не более 10000 x 10000 пикселей.

- Размеры PDF должны быть не более 17 x 17 дюймов, что соответствует размерам бумаги Legal или A3 и меньше.
Предварительный просмотр Read 3.2 позволяет выбрать страницу (ы)
С помощью API предварительного просмотра Read 3.2 для больших многостраничных документов вы можете указать определенные номера страниц или диапазоны страниц в качестве входного параметра для извлечения текста только с этих страниц. Это новый входной параметр в дополнение к необязательному параметру языка.
Примечание
Языковой ввод
Вызов Read имеет необязательный параметр запроса для языка.Это языковой код текста документа BCP-47. Read поддерживает автоматическую идентификацию языка и многоязычные документы, поэтому указывайте код языка только в том случае, если вы хотите, чтобы документ обрабатывался на этом конкретном языке.
Звонок для чтения
Вызов Read API чтения принимает изображение или документ PDF в качестве входных данных и извлекает текст асинхронно. Вызов возвращается с полем заголовка ответа под названием Operation-Location . Значение Operation-Location — это URL-адрес, содержащий идентификатор операции, который будет использоваться на следующем шаге.
| Заголовок ответа | URL-адрес результата |
|---|---|
| Место работы | https: //cognitiveservice/vision/v3.1/read/analyzeResults/49a36324-fc4b-4387-aa06-090cfbf0064f |
Примечание
Биллинг
На странице цен на компьютерное зрение указан уровень цен для чтения. Каждое проанализированное изображение или страница — это одна транзакция. Если вы вызываете операцию с документом PDF или TIFF, содержащим 100 страниц, операция чтения засчитает ее как 100 транзакций, и вам будет выставлен счет за 100 транзакций.Если вы сделали 50 вызовов операции, и каждый вызов отправлял документ со 100 страницами, вам будет выставлен счет за 50 X 100 = 5000 транзакций.
Получите результаты чтения звоните
Второй шаг — вызвать операцию «Получить результаты чтения». Эта операция принимает в качестве входных данных идентификатор операции, созданный операцией чтения. Он возвращает ответ JSON, содержащий поле статуса со следующими возможными значениями. Вы вызываете эту операцию итеративно, пока она не вернет значение успешно выполнено .Используйте интервал от 1 до 2 секунд, чтобы избежать превышения скорости запросов в секунду (RPS).
| Поле | Тип | Возможные значения |
|---|---|---|
| статус | строка | notStarted: операция не началась. |
| работает: операция обрабатывается. | ||
| не удалось: операция не удалась. | ||
| выполнено успешно: операция выполнена успешно. |
Примечание
Уровень бесплатного пользования ограничивает частоту запросов до 20 вызовов в минуту. Платный уровень допускает 10 запросов в секунду (RPS), которые могут быть увеличены по запросу. Используйте канал поддержки Azure или свою команду по работе с клиентами, чтобы запросить более высокую скорость запросов в секунду (RPS).
Когда в поле статуса указано значение преуспело , ответ JSON будет содержать извлеченный текстовый контент из вашего изображения или документа. В ответе JSON сохраняется исходная группировка распознанных слов.Он включает извлеченные текстовые строки и их координаты ограничивающей рамки. Каждая текстовая строка включает все извлеченные слова с их координатами и оценками достоверности.
Примечание
Данные, отправленные для операции Read , временно зашифровываются, хранятся в неактивном состоянии и удаляются в течение 48 часов. Это позволяет вашим приложениям извлекать извлеченный текст как часть ответа службы.
Пример вывода JSON
См. Следующий пример успешного ответа JSON:
{
"status": "успешно",
"createdDateTime": "2020-05-28T05: 13: 21Z",
"lastUpdatedDateTime": "2020-05-28T05: 13: 22Z",
"analysisResult": {
"версия": "3.1.0 ",
"readResults": [
{
"Страница 1,
«угол»: 0,8551,
«ширина»: 2661,
«высота»: 1901 г.,
"unit": "пиксель",
"строки": [
{
"Ограничительная рамка": [
67,
646, г.
2582, г.
713,
2580, г.
876, г.
67,
821
],
"text": "Быстрая коричневая лиса прыгает",
"слова": [
{
"Ограничительная рамка": [
143,
650,
435,
661,
436, г.
823, г.
144,
824
],
"text": "The",
«уверенность»: 0.958
}
]
}
]
}
]
}
}
Предварительный просмотр Read 3.2 добавляет стиль строки текста (только для латинских языков)
API предварительного просмотра Read 3.2 выводит объект внешнего вида , классифицирующий, является ли каждая текстовая строка напечатанным или рукописным стилем, вместе с оценкой достоверности. Эта функция поддерживается только для латинских языков.
Начните работу с быстрым запуском API-интерфейса Computer Vision REST или клиентской библиотеки, чтобы начать интеграцию возможностей распознавания текста в свои приложения.
Поддерживаемые языки для печатного текста
Read API поддерживает извлечение печатного текста на английском, испанском, немецком, французском, итальянском, португальском и голландском языках.
См. Полный список поддерживаемых языков в разделе Поддерживаемые языки.
Read 3.2 превью добавляет упрощенный китайский и японский
В общедоступной предварительной версии Read 3.2 API добавлена поддержка упрощенного китайского и японского языков. Если для вашего сценария требуется поддержка большего количества языков, см. Раздел OCR API.
Поддерживаемые языки для рукописного текста
Операция чтения в настоящее время поддерживает извлечение рукописного текста исключительно на английском языке.
Используйте REST API и SDK
Read 3.x REST API — предпочтительный вариант для большинства клиентов из-за простоты интеграции и быстрой производительности сразу после установки. Azure и служба компьютерного зрения обеспечивают масштабирование, производительность, безопасность данных и соответствие нормативным требованиям, в то время как вы сосредотачиваетесь на удовлетворении потребностей своих клиентов.
Развертывание локально с контейнерами Docker
Контейнер Read Docker (предварительная версия) позволяет развернуть новые возможности OCR в вашей собственной локальной среде.Контейнеры отлично подходят для конкретных требований к безопасности и управлению данными.
Примеры выходов
Текст из изображений
Следующий вывод API чтения показывает извлеченный текст из изображения с разными углами наклона текста, цветами и шрифтами.
Текст из документов
Read API также может принимать PDF-документы в качестве входных данных.
Рукописный текст
Операция чтения извлекает рукописный текст из изображений (в настоящее время только на английском языке).
Печатный текст
Операция чтения позволяет извлекать печатный текст на нескольких языках.
Документы на разных языках
Read API поддерживает изображения и документы на нескольких разных языках, обычно называемые документами на разных языках. Он работает, классифицируя каждую текстовую строку в документе по обнаруженному языку перед извлечением ее текстового содержимого.
OCR API
OCR API использует старую модель распознавания, поддерживает только изображения и выполняется синхронно, немедленно возвращая обнаруженный текст.См. Список поддерживаемых языков OCR, затем прочтите API.
Конфиденциальность и безопасность данных
Как и все когнитивные службы, разработчики, использующие службы чтения / распознавания текста, должны быть осведомлены о политиках Microsoft в отношении данных клиентов. См. Страницу Cognitive Services в Центре управления безопасностью Microsoft, чтобы узнать больше.
Примечание
Операции RecognizeText в Computer Vison 2.0 находятся в процессе устаревания в пользу нового API чтения, описанного в этой статье. Существующие клиенты должны перейти на использование операций чтения.
Следующие шаги
OpenCV OCR и распознавание текста с Tesseract
Щелкните здесь, чтобы загрузить исходный код этого сообщенияВ этом руководстве вы узнаете, как применять OpenCV OCR (оптическое распознавание символов). Мы выполним как (1) обнаружение текста , так и (2) распознавание текста , используя OpenCV, Python и Tesseract.
Несколько недель назад я показал вам, как выполнять обнаружение текста с помощью модели глубокого обучения EAST OpenCV.Используя эту модель, мы смогли обнаружить и локализовать координаты ограничивающего прямоугольника текста, содержащегося в изображении.
Следующий шаг — взять каждую из этих областей, содержащих текст, и фактически распознать и распознать текст с помощью OpenCV и Tesseract.
Чтобы узнать, как создать свою собственную OpenCV OCR и систему распознавания текста, просто продолжайте читать!
OpenCV OCR и распознавание текста с Tesseract
Чтобы выполнить распознавание текста OpenCV OCR, нам сначала нужно установить Tesseract v4, который включает высокоточную модель на основе глубокого обучения для распознавания текста.
Оттуда я покажу вам, как написать сценарий Python, который:
- Выполняет обнаружение текста с помощью детектора текста EAST OpenCV, высокоточного детектора текста с глубоким обучением, используемого для обнаружения текста в естественных изображениях сцены.
- Как только мы обнаружим текстовых областей с помощью OpenCV, мы затем извлечем каждую из текстовых областей интереса и передадим их в Tesseract, позволив нам построить весь конвейер OpenCV OCR!
Наконец, я завершу сегодняшний урок, показав вам несколько примеров результатов применения распознавания текста с помощью OpenCV, а также обсудив некоторые ограничения и недостатки этого метода.
Давайте продолжим и начнем с OpenCV OCR!
Как установить Tesseract 4
Рисунок 1: Механизм распознавания текста Tesseract существует с 1980-х годов. По состоянию на 2018 год он теперь включает встроенную возможность глубокого обучения, что делает его надежным инструментом распознавания текста (просто имейте в виду, что ни одна система OCR не является идеальной). Использование Tesseract с детектором EAST OpenCV дает отличную комбинацию.Tesseract, очень популярный движок OCR, изначально был разработан Hewlett Packard в 1980-х годах, а затем в 2005 году был открыт исходный код.Google принял проект в 2006 году и с тех пор спонсирует его.
Если вы читали мой предыдущий пост о Использование Tesseract OCR с Python , вы знаете, что Tesseract может очень хорошо работать в контролируемых условиях…
… но будет работать довольно плохо, если будет много шума или ваше изображение не будет должным образом предварительно обработано и очищено перед применением Tesseract.
Подобно тому, как глубокое обучение повлияло почти на каждого аспекта компьютерного зрения, то же самое верно и для распознавания символов и распознавания почерка.
Модели, основанные на глубоком обучении, смогли обеспечить беспрецедентную точность распознавания текста, выходящую далеко за рамки традиционных подходов к извлечению признаков и машинному обучению.
Это был лишь вопрос времени, когда Tesseract включит модель глубокого обучения для дальнейшего повышения точности распознавания текста — и, по сути, это время пришло.
Последняя версия Tesseract (v4) поддерживает OCR на основе глубокого обучения, что на значительно точнее на .
Сам базовый механизм OCR использует сеть с длительной краткосрочной памятью (LSTM), своего рода рекуррентную нейронную сеть (RNN).
В оставшейся части этого раздела вы узнаете, как установить Tesseract v4 на свой компьютер.
Позже в этом сообщении блога вы узнаете, как объединить алгоритм обнаружения текста EAST OpenCV с Tesseract v4 в едином скрипте Python для автоматического выполнения OpenCV OCR.
Приступим к настройке вашей машины!
Установить OpenCV
Для запуска сегодняшнего скрипта вам понадобится установленный OpenCV. Требуется версия 3.4.2 или выше.
Чтобы установить OpenCV в вашей системе, просто следуйте одному из моих руководств по установке OpenCV, убедившись, что вы загружаете правильную / желаемую версию OpenCV и OpenCV-contrib в процессе.
Установите Tesseract 4 на Ubuntu
Точные команды, используемые для установки Tesseract 4 в Ubuntu, будут различаться в зависимости от того, используете ли вы Ubuntu 18.04 или Ubuntu 17.04 или более ранние версии.
Чтобы проверить свою версию Ubuntu, вы можете использовать команду lsb_release :
$ lsb_release -a Модулей LSB нет.Идентификатор распространителя: Ubuntu Описание: Ubuntu 18.04.1 LTS Релиз: 18.04 Кодовое имя: бионический
Как видите, я использую Ubuntu 18.04, но прежде чем продолжить, вам следует проверить свою версию Ubuntu.
Для пользователей Ubuntu 18.04 Tesseract 4 является частью основного репозитория apt-get, что упрощает установку Tesseract с помощью следующей команды:
$ sudo apt установить tesseract-ocr
Если вы используете Ubuntu 14, 16 или 17, вам понадобится несколько дополнительных команд из-за требований зависимости.
Хорошая новость заключается в том, что Александр Поздняков создал Ubuntu PPA (Personal Package Archive) для Tesseract, что упрощает установку Tesseract 4 на более старые версии Ubuntu.
Просто добавьте репозиторий PPA alex-p / tesseract-ocr в вашу систему, обновите определения пакетов и затем установите Tesseract:
$ sudo add-apt-репозиторий ppa: alex-p / tesseract-ocr $ sudo apt-get update $ sudo apt установить tesseract-ocr
Если ошибок нет, теперь на вашем компьютере должен быть установлен Tesseract 4.
Установите Tesseract 4 на macOS
Установить Tesseract на macOS просто при условии, что в вашей системе установлен Homebrew, «неофициальный» менеджер пакетов macOS.
Просто выполните следующую команду, и на вашем Mac будет установлен Tesseract v4:
$ brew установить tesseract
2020-07-21 Обновление: Tesseract 5 (альфа-релиз) доступен. В настоящее время мы рекомендуем использовать Tesseract 4. Если вам нужна последняя версия Tesseract (на момент написания этой статьи это 5.0.0-alpha), затем обязательно добавьте переключатель --HEAD в конце команды.
Если у вас уже установлен Tesseract на вашем Mac (например, если вы следовали моему предыдущему руководству по установке Tesseract), вам сначала нужно отменить связь с исходной установкой:
$ brew отключить тессеракт
И оттуда вы можете запустить команду установки.
Проверьте версию Tesseract
Рисунок 2: Снимок экрана моего системного терминала, где я ввел команду tesseract -v для запроса версии.Я подтвердил, что у меня установлен Tesseract 4.После того, как Tesseract установлен на вашем компьютере, вы должны выполнить следующую команду, чтобы проверить версию Tesseract:
$ тессеракт -v тессеракт 4.0.0-бета.3 лептоника-1,76,0 libjpeg 9c: libpng 1.6.34: libtiff 4.0.9: zlib 1.2.11 Нашел AVX512BW Нашел AVX512F Нашел AVX2 Нашел AVX Найден SSE
Пока вы видите tesseract 4 где-то в выводе, вы знаете, что в вашей системе установлена последняя версия Tesseract.
Установите привязки Tesseract + Python
Теперь, когда у нас установлен двоичный файл Tesseract, нам нужно установить привязки Tesseract + Python, чтобы наши сценарии Python могли взаимодействовать с Tesseract и выполнять OCR для изображений, обработанных OpenCV.
Если вы используете виртуальную среду Python (которую я настоятельно рекомендую, чтобы у вас были отдельные независимые среды Python), используйте команду workon для доступа к вашей виртуальной среде:
$ workon cv
В этом случае я получаю доступ к виртуальной среде Python с именем cv (сокращение от «компьютерное зрение») — вы можете заменить cv тем, что вы назвали своей виртуальной средой.
Далее мы будем использовать pip для установки Pillow, более удобной для Python версии PIL, за которым следуют pytesseract и imutils :
$ pip install подушка $ pip установить pytesseract $ pip install imutils
Теперь откройте оболочку Python и подтвердите, что вы можете импортировать как OpenCV, так и pytesseract :
$ питон Python 3.6.5 (по умолчанию, 1 апреля 2018 г., 05:46:30) [GCC 7.3.0] в Linux Для получения дополнительной информации введите «помощь», «авторские права», «кредиты» или «лицензия».>>> импортировать cv2 >>> импортировать pytesseract >>> импортировать imutils >>>
Поздравляем!
Если вы не видите никаких ошибок при импорте, значит, ваш компьютер настроен на выполнение OCR и распознавания текста с помощью OpenCV
.Давайте перейдем к следующему разделу (пропуская инструкции Pi), где мы узнаем, как на самом деле реализовать скрипт Python для выполнения OpenCV OCR.
Установите Tesseract 4 и вспомогательное программное обеспечение на Raspberry Pi и Raspbian
Примечание: Вы можете пропустить этот раздел, если у вас нет Raspberry Pi.
Меня неизбежно спросят, как установить Tesseract 4 на Rasberry Pi.
Следующие инструкции не для слабонервных — у вас могут возникнуть проблемы. Они протестированы, но пробег может отличаться на вашем собственном Raspberry Pi.
Сначала удалите привязки OpenCV из пакетов системного сайта:
$ sudo rm /usr/local/lib/python3.5/site-packages/cv2.so
Здесь я использовал команду rm , так как мой файл cv2.so в site-packages — это просто символическая ссылка.Если привязки cv2.so — это ваши настоящие привязки OpenCV, тогда вы можете переместить файл из site-packages для безопасного хранения.
Теперь установите два пакета QT в вашей системе:
$ sudo apt-get install libqtgui4 libqt4-test
Затем установите tesseract через Thortex GitHub:
$ cd ~ $ git clone https://github.com/thortex/rpi3-tesseract $ cd rpi3-tesseract / релиз $ ./install_requires_related2leptonica.sh $./install_requires_related2tesseract.sh $ ./install_tesseract.sh
По какой-то причине файл данных обученного английского языка отсутствовал при установке, поэтому мне нужно было загрузить и переместить его в соответствующий каталог:
$ cd ~ $ wget https://github.com/tesseract-ocr/tessdata/raw/master/eng.traineddata $ sudo mv -v eng.traineddata / usr / local / share / tessdata /
Оттуда создайте новую виртуальную среду Python:
$ mkvirtualenv cv_tesseract -p python3
И установить необходимые пакеты:
$ работа на cv_tesseract $ pip install opencv-contrib-python imutils подушка pytesseract
Готово! Просто имейте в виду, что ваш опыт может отличаться.
Понимание OpenCV OCR и распознавания текста Tesseract
Рисунок 3: Конвейер OpenCV OCR.Теперь, когда в нашей системе успешно установлены OpenCV и Tesseract, нам необходимо кратко рассмотреть наш конвейер и связанные с ним команды.
Для начала мы применим детектор текста EAST OpenCV для определения наличия текста в изображении. Детектор текста EAST выдаст нам ограничивающую рамку (x, y) — координаты текстовых областей интереса.
Мы извлечем каждую из этих областей интереса, а затем передадим их в алгоритм распознавания текста LSTM Deep Learning в Tesseract v4.
Вывод LSTM даст нам наши фактические результаты OCR.
Наконец, мы нарисуем результаты OpenCV OCR на нашем выходном изображении.
Но прежде чем мы фактически перейдем к нашему проекту, давайте кратко рассмотрим команду Tesseract (которая будет вызываться изнутри библиотекой pytesseract ).
При вызове бинарного файла tessarct нам необходимо указать несколько флагов. Три наиболее важных: -l , --oem и --psm .
Флаг -l управляет языком вводимого текста. В этом примере мы будем использовать eng (английский), но вы можете увидеть все языки, поддерживаемые Tesseract здесь.
Аргумент --oem , или режим OCR Engine, управляет типом алгоритма, используемого Tesseract.
Вы можете увидеть доступные режимы модуля OCR, выполнив следующую команду:
$ tesseract --help-oem Режимы OCR Engine: 0 Только устаревший движок. 1 Нейронные сети Только движок LSTM.2 движка Legacy + LSTM. 3 По умолчанию, в зависимости от того, что доступно.
Мы будем использовать --oem 1 , чтобы указать, что мы хотим использовать только механизм глубокого обучения LSTM.
Последний важный флаг, --psm , управляет автоматическим режимом сегментации страниц, используемым Tesseract:
$ tesseract --help-psm
Режимы сегментации страницы:
0 Только ориентация и обнаружение сценария (OSD).
1 Автоматическая сегментация страниц с помощью экранного меню.
2 Автоматическая сегментация страниц, без OSD или OCR.3 Полностью автоматическая сегментация страниц, но без экранного меню. (По умолчанию)
4 Предположим, что один столбец текста переменного размера.
5 Представьте себе единый однородный блок вертикально выровненного текста.
6 Предположим, что это один однородный блок текста.
7 Рассматривайте изображение как одну текстовую строку.
8 Относитесь к изображению как к одному слову.
9 Рассматривайте изображение как отдельное слово в круге.
10 Относитесь к изображению как к одному символу.
11 Редкий текст. Найдите как можно больше текста в произвольном порядке.
12 Разреженный текст с экранным меню.13 Необработанная линия. Рассматривайте изображение как одну текстовую строку,
обход хаков, специфичных для Tesseract.
Для РИ текста OCR я обнаружил, что режимы 6 и 7 работают хорошо, но если вы OCR обрабатываете большие блоки текста, вы можете попробовать 3 , режим по умолчанию.
Каждый раз, когда вы обнаруживаете, что получаете неверные результаты OCR, я настоятельно рекомендую настроить --psm , так как это может существенно повлиять на ваши выходные результаты OCR.
Структура проекта
Обязательно возьмите zip из раздела «Загрузки» сообщения в блоге.
Оттуда распакуйте файл и перейдите в каталог. Команда tree позволяет нам увидеть структуру каталогов в нашем терминале:
$ tree --dirsfirst . ├── изображения │ ├── example_01.jpg │ ├── example_02.jpg │ ├── example_03.jpg │ ├── example_04.jpg │ └── example_05.jpg ├── frozen_east_text_detection.pb └── text_recognition.py 1 каталог, 7 файлов
Наш проект содержит один каталог и два известных файла:
-
изображения /: Каталог, содержащий шесть тестовых изображений, содержащих текст сцены. Мы попробуем OpenCV OCR с каждым из этих изображений. -
frozen_east_text_detection.pb: Детектор текста EAST. Этот CNN предварительно обучен для обнаружения текста и готов к работе. Я не обучал эту модель — она поставляется с OpenCV; Я также включил его в «Загрузки» для вашего удобства. -
text_recognition.py: Наш скрипт для распознавания текста — мы рассмотрим этот скрипт построчно. Скрипт использует детектор текста EAST для поиска областей текста на изображении, а затем использует Tesseract v4 для распознавания.
Реализация нашего алгоритма OpenCV OCR
Теперь мы готовы выполнить распознавание текста с помощью OpenCV!
Откройте файл text_recognition.py и вставьте следующий код:
# импортируем необходимые пакеты от imutils.object_detection импорт non_max_suppression импортировать numpy как np импортировать pytesseract import argparse импорт cv2
Сегодняшний сценарий OCR требует пяти операций импорта, один из которых встроен в OpenCV.
В частности, мы будем использовать pytesseract и OpenCV. Мой пакет imutils будет использоваться для подавления не максимальных значений, поскольку функция OpenCV NMSBoxes , похоже, не работает с API Python. Также отмечу, что NumPy является зависимостью от OpenCV.
Пакет argparse входит в состав Python и обрабатывает аргументы командной строки — устанавливать нечего.
Теперь, когда мы позаботились об импорте, давайте реализуем функцию decode_predictions :
def decode_predictions (оценки, геометрия): # возьмите количество строк и столбцов из объема оценок, затем # инициализируем наш набор прямоугольников ограничивающей рамки и соответствующие # показатель достоверности (numRows, numCols) = баллы.форма [2: 4] rects = [] уверенность = [] # перебираем количество строк для y в диапазоне (0, numRows): # извлекаем оценки (вероятности), а затем # геометрические данные, используемые для получения потенциальной ограничивающей рамки # координаты, окружающие текст scoresData = scores [0, 0, y] xData0 = geometry [0, 0, y] xData1 = geometry [0, 1, y] xData2 = geometry [0, 2, y] xData3 = geometry [0, 3, y] anglesData = geometry [0, 4, y] # перебрать количество столбцов для x в диапазоне (0, numCols): # если наша оценка не имеет достаточной вероятности, # игнорируй это если scoresData [x]Функция
decode_predictionsначинается в строке 8 и подробно объясняется в сообщении об обнаружении текста EAST. Функция:
- Использует детектор текста на основе глубокого обучения для обнаружения (не распознанных) областей текста на изображении.
- Детектор текста создает два массива, один из которых содержит вероятности данной области, содержащей текст, а другой сопоставляет счет с положением ограничивающей рамки во входном изображении.
Как мы увидим в нашем конвейере OpenCV OCR, модель детектора текста EAST будет выдавать две переменные:
баллов: Вероятности положительных текстовых областей.геометрия: ограничивающие рамки текстовых областей.… каждый из которых является параметром функции
decode_predictions.Функция обрабатывает эти входные данные, в результате чего получается кортеж, содержащий (1) положения ограничивающего прямоугольника текста и (2) соответствующую вероятность того, что область, содержащая текст:
rects: Это значение основано на геометриии имеет более компактную форму, чтобы мы могли позже применить NMS.достоверности: Значения достоверности в этом списке соответствуют каждому прямоугольнику впрямоугольниках.Оба эти значения возвращаются функцией.
Примечание: В идеале, повернутый ограничивающий прямоугольник должен быть включен в
прямоугольников, но не совсем просто извлечь повернутый ограничивающий прямоугольник для сегодняшнего доказательства концепции. Вместо этого я вычислил горизонтальный ограничивающий прямоугольник, который учитывает угол°.Уголдоступен в строке , строка 41, , если вы хотите извлечь повернутую ограничивающую рамку слова для передачи в Tesseract.Дополнительные сведения о блоке кода выше см. В этом сообщении в блоге.
Оттуда давайте проанализируем наши аргументы командной строки:
# создать парсер аргументов и проанализировать аргументы ap = argparse.ArgumentParser () ap.add_argument ("- i", "--image", type = str, help = "путь к входному изображению") ap.add_argument ("- восток", "- восток", type = str, help = "путь к входному детектору текста EAST") ap.add_argument ("- c", "--min-достоверность", type = float, по умолчанию = 0,5, help = "минимальная вероятность, необходимая для осмотра региона") ap.add_argument ("- w", "--width", type = int, по умолчанию = 320, help = "ближайшее кратное 32 для измененной ширины") ap.add_argument ("- e", "--height", type = int, по умолчанию = 320, help = "ближайшее кратное 32 для высоты измененного размера") ap.add_argument ("- p", "--padding", type = float, по умолчанию = 0.0, help = "количество отступов, добавляемых к каждой границе области интереса") args = vars (ap.parse_args ())Наш сценарий требует двух аргументов командной строки:
--image: путь к входному изображению.--east: путь к предварительно обученному детектору текста EAST.Дополнительно могут быть предоставлены следующие аргументы командной строки:
--min-достоверность: минимальная вероятность обнаруженной текстовой области.--width: ширина нашего изображения будет изменена до прохождения через детектор текста EAST.Нашему детектору требуется число, кратное 32.--height: То же, что и ширина, но для высоты. Опять же, нашему детектору требуется кратное32для измененной высоты.--padding: (необязательно) количество отступов, добавляемых к каждой границе области интереса. Вы можете попробовать значения0,05для 5% или0,10для 10% (и так далее), если вы обнаружите, что ваш результат OCR неверен.Оттуда мы загрузим + предварительно обработаем наше изображение и инициализируем ключевые переменные:
# загружаем входное изображение и получаем размеры изображения изображение = cv2.imread (args ["изображение"]) orig = image.copy () (origH, origW) = image.shape [: 2] # установить новую ширину и высоту, а затем определить соотношение изменения # для ширины и высоты (newW, newH) = (args ["ширина"], args ["высота"]) rW = origW / float (newW) rH = origH / float (newH) # изменить размер изображения и получить новые размеры изображения изображение = cv2.resize (изображение, (newW, newH)) (H, W) = image.shape [: 2]Наше изображение
загружается в память и копируется (чтобы позже мы могли рисовать на нем наши выходные результаты) на , строки 82 и 83 .Мы берем исходную ширину и высоту ( Line 84 ), а затем извлекаем новую ширину и высоту из словаря
args( Line 88 ).Используя как исходные, так и новые размеры, мы вычисляем коэффициенты, используемые для масштабирования координат нашей ограничивающей рамки позже в скрипте (, строки 89 и 90, ).
Наше изображение
затем изменяется, игнорирует соотношение сторон ( Line 93 ).Далее поработаем с детектором текста EAST:
# определяем два имени выходного слоя для модели детектора EAST, которая # нас интересуют - во-первых, вероятности выхода и # секунда может использоваться для получения координат ограничивающего прямоугольника текста layerNames = [ "feature_fusion / Conv_7 / Sigmoid", "feature_fusion / concat_3"] # загружаем предварительно обученный детектор текста EAST print ("[ИНФОРМАЦИЯ] загрузка детектора текста EAST ...") net = cv2.dnn.readNet (args ["восток"])Наши два имени выходного слоя помещены в список в строках 99-101 .Чтобы узнать, почему эти два имени вывода важны, обратитесь к моему оригинальному руководству по обнаружению текста EAST.
Затем наша предварительно обученная нейронная сеть EAST загружается в память (, строка 105, ).
Я не могу этого особо подчеркнуть: вам понадобится OpenCV 3.4.2 как минимум для реализации
cv2.dnn.readNet.Первая «магия» происходит следующим образом:
# создать каплю из изображения, а затем выполнить прямой проход # модель для получения двух наборов выходных слоев blob = cv2.dnn.blobFromImage (изображение, 1.0, (Ш, В), (123.68, 116.78, 103.94), swapRB = True, crop = False) net.setInput (большой двоичный объект) (оценки, геометрия) = net.forward (layerNames) # расшифровать предсказания, затем применить немаксимальное подавление к # подавить слабые, перекрывающиеся ограничивающие рамки (rects, уверенность) = decode_predictions (оценки, геометрия) коробки = non_max_suppression (np.array (rects), probs = достоверность)Для определения местоположения текста мы:
- Создайте большой двоичный объект
на строках 109 и 110 .Подробнее о процессе читайте здесь.- Передайте большой двоичный объект
через нейронную сеть, получивбалловигеометрии( строки 111 и 112 ).- Декодируйте прогнозы с помощью ранее определенной функции
decode_predictions(, строка 116, ).- Примените подавление не максимальных значений с помощью моего метода imutils (, строка 117, ). NMS эффективно берет наиболее вероятные текстовые области, устраняя другие перекрывающиеся области.
Теперь, когда мы знаем, где текстовые области , нам нужно предпринять шаги, чтобы распознать текст! Мы начинаем перебирать ограничивающие рамки и обрабатывать результаты, готовя сцену для фактического распознавания текста :
# инициализировать список результатов результаты = [] # перебрать ограничительные рамки для (startX, startY, endX, endY) в полях: # масштабируем координаты ограничивающего прямоугольника на основе соответствующих # соотношения startX = int (startX * rW) startY = int (startY * rH) конецX = число (конецX * rW) конец Y = int (конец Y * rH) # для лучшего распознавания текста мы потенциально можем # примените немного отступов вокруг ограничивающей рамки - здесь мы # вычисляем дельты в направлениях x и y dX = int ((endX - startX) * args ["заполнение"]) dY = int ((endY - startY) * args ["заполнение"]) # применяем отступы к каждой стороне ограничивающего прямоугольника соответственно startX = max (0, startX - dX) startY = max (0, startY - dY) endX = min (origW, endX + (dX * 2)) endY = min (origH, endY + (dY * 2)) # извлекаем фактическую ROI с заполнением roi = orig [начало: конецY, началоX: конецX]Мы инициализируем список
результатов, чтобы он содержал ограничительные рамки OCR и текст в строке , 120, .Затем мы начинаем перебирать
прямоугольников(, строка 123, ), где мы:
- Масштабируйте ограничивающие рамки на основе ранее вычисленных соотношений (, строки 126-129, ).
- Заполните ограничительные рамки ( линии 134-141 ).
- И, наконец, извлеките заполненный
roi(, строка 144, ).Наш конвейер OpenCV OCR можно завершить, используя немного «магии» Tesseract v4:
# чтобы применить Tesseract v4 к тексту OCR, мы должны предоставить # (1) язык, (2) OEM-флаг 4, указывающий, что мы # хотите использовать модель нейронной сети LSTM для распознавания текста, и, наконец, # (3) значение OEM, в данном случае 7, что означает, что мы # обрабатываем ROI как одну строку текста config = ("-l eng --oem 1 --psm 7") текст = pytesseract.image_to_string (roi, config = config) # добавляем в список координаты ограничивающего прямоугольника и текст OCR # результатов results.append (((началоX, началоY, конецX, конецY), текст))Принимая к сведению комментарий в кодовом блоке, мы устанавливаем параметры конфигурации Tesseract
в строке 151 ( английский язык , нейронная сеть LSTM и однострочный текст e).Примечание: Вам может потребоваться настроить значение
--psm, используя мои инструкции в верхней части этого руководства, если вы обнаружите, что получаете неправильные результаты распознавания текста.Библиотека
pytesseractпозаботится обо всем остальном на Строке 152 , где мы вызываемpytesseract.image_to_string, передавая нашу строку конфигурацииroiи.? Бум! В двух строках кода вы использовали Tesseract v4 для распознавания текстовой области интереса на изображении. Просто помните, много всего происходит под капотом .
Наш результат (значения ограничивающей рамки и фактическая строка
текста) добавляется к списку результатов( строка 156 ).Затем мы продолжаем этот процесс для других областей интереса в верхней части цикла.
Теперь давайте отобразим / распечатаем результаты, чтобы убедиться, что это действительно сработало:
# сортируем координаты ограничивающего прямоугольника результатов сверху вниз результаты = отсортировано (результаты, ключ = лямбда r: r [0] [1]) # перебрать результаты for ((startX, startY, endX, endY), text) в результатах: # отображать текст, опознанный Tesseract print ("OCR TEXT") print ("========") print ("{} \ n" .format (текст)) # вырезать не-ASCII текст, чтобы мы могли нарисовать текст на изображении # используя OpenCV, затем нарисуйте текст и ограничивающую рамку вокруг # текстовая область входного изображения текст = "".join ([c if ord (c) <128 else "" вместо c в тексте]). strip () output = orig.copy () cv2.rectangle (вывод, (startX, startY), (endX, endY), (0, 0, 255), 2) cv2.putText (вывод, текст, (startX, startY - 20), cv2.FONT_HERSHEY_SIMPLEX, 1.2, (0, 0, 255), 3) # показать выходное изображение cv2.imshow ("Обнаружение текста", вывод) cv2.waitKey (0)Наши результаты:
отсортированосверху вниз по строке 159 на основе y -координаты ограничивающей рамки (хотя вы можете захотеть отсортировать их по-другому).Оттуда, перебирая результаты
, мы:
- Распечатать OCR’d
текстна терминал ( строки 164–166, ).- Удалите символы, отличные от ASCII, из текста
, поскольку OpenCV не поддерживает символы, отличные от ASCII, в функцииcv2.putText(, строка 171, ).- Нарисуйте (1) ограничивающую рамку, окружающую область интереса, и (2) результат
текстнад областью интереса ( строки 173-176, ).- Отобразите результат и дождитесь нажатия любой клавиши (, строки 179 и 180, ).
Результаты распознавания текста OpenCV
Теперь, когда мы реализовали конвейер OpenCV OCR, давайте посмотрим, как он работает.
Обязательно используйте раздел «Загрузки» этого сообщения в блоге, чтобы загрузить исходный код, модель детектора текста OpenCV EAST и примеры изображений.
Оттуда откройте командную строку, перейдите туда, где вы загрузили + извлекли zip-архив, и выполните следующую команду:
$ python text_recognition.py --east frozen_east_text_detection.pb \ --image images / example_01.jpg [ИНФОРМАЦИЯ] загрузка детектора текста EAST ... OCR TEXT ======== Ой хорошоРисунок 4: Наше первое испытание OpenCV OCR прошло успешно.Начнем с простого примера.
Обратите внимание, как наша система OpenCV OCR смогла правильно (1) обнаружить текст на изображении, а затем (2) также распознать текст.
Следующий пример более представительный текст, который мы видим на реальном изображении:
$ python text_recognition.py --east frozen_east_text_detection.pb \ --image images / example_02.jpg [ИНФОРМАЦИЯ] загрузка детектора текста EAST ... OCR TEXT ======== ® СРЕДНИЙРисунок 5: Более сложное изображение знака с белым фоном - это OCR’d с OpenCV и Tesseract 4.Опять же, обратите внимание, как наш конвейер OpenCV OCR смог правильно локализовать и распознать текст; однако в выходных данных нашего терминала мы видим зарегистрированный товарный знак Unicode - вероятно, Tesseract был сбит с толку, поскольку ограничивающая рамка, о которой сообщил детектор текста EAST OpenCV, просочилась в травянистые кусты / растения за знаком.
Давайте посмотрим на другой пример OpenCV OCR и распознавания текста:
$ python text_recognition.py --east frozen_east_text_detection.pb \ --image images / example_03.jpg [ИНФОРМАЦИЯ] загрузка детектора текста EAST ... OCR TEXT ======== НЕДВИЖИМОСТЬ OCR TEXT ======== АГЕНТЫ OCR TEXT ======== САКСОНЫРисунок 6: Большой знак, содержащий три слова, правильно распознается с помощью OpenCV, Python и Tesseract.
В этом случае есть три отдельных текстовых области.
Детектор текстаOpenCV может локализовать каждый из них - затем мы применяем OCR для правильного распознавания каждой текстовой области.
Наш следующий пример показывает важность добавления отступов в определенных обстоятельствах:
$ python text_recognition.py --east frozen_east_text_detection.pb \ --image images / example_04.jpg [ИНФОРМАЦИЯ] загрузка детектора текста EAST ... OCR TEXT ======== CAPTITO OCR TEXT ======== МАГАЗИН OCR TEXT ======== |,Рисунок 7: У нашего конвейера OpenCV OCR есть проблемы с текстовыми областями, идентифицированными детектором EAST OpenCV в этой сцене кондитерской.Имейте в виду, что ни одна система распознавания текста не может быть идеальной во всех случаях. Но можем ли мы добиться большего, изменив некоторые параметры?
При первой попытке оптического распознавания текста этой витрины кондитерской мы видим, что «МАГАЗИН» правильно опознается, но:
- Буква «U» в «CAPUTO» неправильно распознается как «TI».
- Апостроф и буква «S» отсутствуют в «CAPUTO’S».
- И, наконец, «BAKE» неправильно распознается как вертикальная черта / вертикальная черта («|») с точкой («.»).
Добавив немного отступов, мы можем расширить координаты ограничивающей рамки области интереса и правильно распознать текст:
$ python text_recognition.py --east frozen_east_text_detection.pb \ --image images / example_04.jpg --padding 0,05 [ИНФОРМАЦИЯ] загрузка детектора текста EAST ... OCR TEXT ======== КАПУТО OCR TEXT ======== МАГАЗИН OCR TEXT ======== ПЕЧЬРисунок 8: Добавляя дополнительные отступы вокруг текстовых областей, идентифицированных детектором текста EAST, мы можем правильно распознавать три слова в этой вывеске кондитерской с помощью OpenCV и Tesseract. См. Предыдущий рисунок для первой неудачной попытки.
Просто добавив 5% отступа вокруг каждого угла ограничительной рамки, мы не только сможем правильно распознавать текст «BAKE», но также можем распознать «U» и «S» в «CAPUTO'S» .
Конечно, есть примеры, когда OpenCV терпит неудачу:
$ python text_recognition.py --east frozen_east_text_detection.pb \ --image images / example_05.jpg --padding 0.25 [ИНФОРМАЦИЯ] загрузка детектора текста EAST ... OCR TEXT ======== Дизайнер OCR TEXT ======== аРисунок 9: С отступом в 25% мы можем распознать «Designer» в этом знаке, но наша система OpenCV OCR не работает с более мелкими словами из-за того, что цвет похож на фон.Мы даже не можем распознать слово «SUIT», а пока обнаружено «FACTORY», мы не можем распознать текст с помощью Tesseract. Наша система OCR далека от совершенства.
Я увеличил отступ до 25%, чтобы учесть угол / перспективу слов в этом знаке. Это позволило «Конструктору» правильно распознавать текст с помощью EAST и Tesseract v4. Но слова меньшего размера - безнадежное дело, вероятно, из-за того же цвета букв, что и фон.
В этих ситуациях мы мало что можем сделать, но я бы посоветовал обратиться к разделу ограничений и недостатков ниже, чтобы узнать, как улучшить конвейер распознавания текста OpenCV при столкновении с неверными результатами OCR.
Ограничения и недостатки
Важно понимать, что ни одна система распознавания текста не идеальна!
Не бывает идеального механизма распознавания текста, особенно в реальных условиях.
И, кроме того, ожидать 100% точного оптического распознавания символов - это просто нереально .
Как мы выяснили, наша система OpenCV OCR хорошо работала на одних изображениях, а на других не работала.
Есть две основные причины, по которым мы увидим сбой нашего конвейера распознавания текста:
- Текст перекошен / повернут.
- Шрифт самого текста не похож на тот, на котором обучалась модель Tesseract.
Хотя Tesseract v4 значительно мощнее и точнее Tesseract v3, модель глубокого обучения по-прежнему ограничена данными, на которых она была обучена - если ваш текст содержит украшенные шрифты или шрифты, на которых Tesseract не был обучен, маловероятно, что Tesseract сможет распознавать текст.
Во-вторых, имейте в виду, что Tesseract по-прежнему предполагает , что ваше входное изображение / ROI относительно очищены.
Поскольку мы выполняем обнаружение текста в изображениях естественной сцены, это предположение не всегда выполняется.
В целом, вы обнаружите, что наш конвейер OpenCV OCR лучше всего работает с текстом, который (1) снят под углом 90 градусов (т. Е. Сверху вниз, с высоты птичьего полета) изображения и (2) относительно легко сегментировать от фона.
Если это не так, вы можете применить перспективное преобразование для исправления вида, но имейте в виду, что рассмотренный сегодня детектор текста Python + EAST не предоставляет повернутые ограничивающие рамки (как обсуждалось в моем предыдущем посте), так что вы все равно будете немного ограничены.
Tesseract всегда будет лучше всего работать с чистыми, предварительно обработанными изображениями, поэтому имейте это в виду, когда вы создаете конвейер OpenCV OCR.
Если вам нужна более высокая точность и ваша система будет иметь подключение к Интернету , я предлагаю вам попробовать одну из «большой тройки» служб API компьютерного зрения:
… каждый из которых использует еще более продвинутые подходы OCR, работающие на мощных машинах в облаке.
Сводка
В сегодняшнем руководстве вы узнали, как применять OpenCV OCR для выполнения обоих:
- Обнаружение текста
- Распознавание текста
Для выполнения этой задачи мы:
- Используется детектор текста EAST OpenCV, позволяющий применять глубокое обучение для локализации областей текста на изображении.
- Оттуда мы извлекли каждую из текстовых областей интереса, а затем применили распознавание текста с помощью OpenCV и Tesseract v4.
Мы также рассмотрели код Python для выполнения как обнаружения текста, так и распознавания текста в одном скрипте.
Наш конвейер OpenCV OCR работал хорошо в некоторых случаях, но также не работал в других. Для наилучших результатов распознавания текста OpenCV я бы посоветовал вам убедиться:
- Ваши входные ROI очищаются и предварительно обрабатываются в максимально возможной степени. В идеальном мире ваш текст был бы идеально отделен от остального изображения, но в действительности это не всегда возможно.
- Ваш текст был снят под углом 90 градусов от камеры, как при виде сверху вниз с высоты птичьего полета. Если это не так, перспективное преобразование может помочь вам получить лучшие результаты.
Надеюсь, вам понравилась сегодняшняя запись в блоге о OpenCV OCR и распознавании текста!
Чтобы получать уведомления о публикации будущих сообщений в блоге на PyImageSearch (включая учебные пособия по распознаванию текста), не забудьте ввести свой адрес электронной почты в форму ниже!
Загрузите исходный код и БЕСПЛАТНОЕ 17-страничное руководство по ресурсам
Введите свой адрес электронной почты ниже, чтобы получить.zip кода и БЕСПЛАТНОЕ 17-страничное руководство по ресурсам по компьютерному зрению, OpenCV и глубокому обучению. Внутри вы найдете мои тщательно отобранные учебники, книги, курсы и библиотеки, которые помогут вам освоить CV и DL!
Распознавание текстаOCR | Продукция
.
- Продукты
- Программные решения Scandit
- Сканирование штрих-кода
- Распознавание текста (OCR)
- Дополненная реальность (AR)
- Добавить Scandit в собственные приложения
- SDK сканера штрих-кода
- Клин для клавиатуры
- Добавить Scandit на сайты
- SDK для Интернета
- Корпоративный браузер
Демо-приложения Узнать цену
- Дополнительные опции
- MatrixScan
- ID сканирование
- Устройства OEM
- → Опора
- → Производительность
- Отрасли
- Все отрасли
- Розничная торговля
- Здравоохранение
- Воздушное путешествие
- Почта, посылка и экспресс
- Производство
Примеры из практики Ресурсы Демо-приложения О поддержке
- Полевая служба
- Прочие отрасли
- Партнеры
Видео Белые бумаги Примеры из практики
- Партнеры
- Партнер Scandit
- Глобальные стратегические альянсы
- Найдите партнера
- Разработчики
- Разработчики
- Документация
- Отправить запрос в службу поддержки
- FAQ
Узнать цену Демо-приложения О поддержке
- Скачать бесплатную пробную версию
- Тестовый собственный SDK
- Тестовый клин для клавиатуры
- Тестовый браузер предприятия
- Тестовый SDK для Интернета
- Ресурсы
- Изучить все ресурсы
- Примеры из практики
- электронных книг
- Направляющие
- Инфографика
- Отчеты
- Инструменты
- Вебинары
- Видео
- Узнать цену
- Попробовать демонстрационные приложения
- Генератор штрих-кода
- Поиск UPC
- Блог
- Около
- Компания
- Менеджмент
Ресурсы Продукты Связаться с нами
- Карьера
- Пресс
- Выберите языкEnglishDeutschFrançaisEspañolItaliano 日本語 Войти Свяжитесь с нами
Leave a Comment